本文转载自,原文
尽管在.net framework中我们不太需要关注内存管理和垃圾回收这方面的问题,但是出于提高我们应用程序性能的目的,在我们的脑子里还是需要有这方面的意识。明白内存管理的基本行为将有助于我们解释我们程序中变量是如何操作的。在本文中我将讨论栈和堆的一些基本知识,变量的类型和某些变量的工作原理。
当你在执行程序的时候内存中有两个地方用于存储程序变量。如果你还不知道,那么就来看看堆和栈的概念。堆和栈都是用于帮助我们程序运行的,包含某些特殊信息的操作系统内存模块。那么堆和栈有什么不同呢?堆VS栈的区别栈主要用于存储代码,自动变量等信息;而堆则主要用于存储运行期生成的对象等信息。将栈看作是一个有着层级关系的盒子,我们每一次只能操作盒子最上一格的东西。这也就是栈先进后出的数据结构特性。因此栈在我们程序中主要是用于保存程序运行时的一些状态信息。堆则主要是用于保存对象内容,以便我们能够在任何时候去访问这些对象。总的来说,堆就是一种数据结构,我们不需要通过一套规则,可以随时访问的内存区域;栈则总是依据先进后出的,每次只能访问最顶层元素的内存区域。下面是个示意图: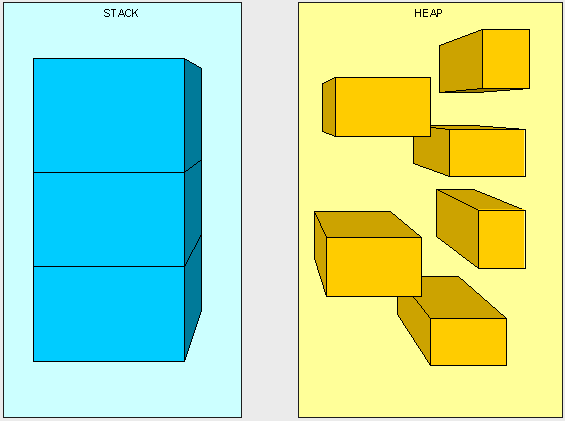
由于栈的特性所至,所以栈具有自我维护性,栈的内存管理可以通过操作系统来完成。而堆的管理就需要通过GC(垃圾回收器)来完成,使用一定的算法来扫描并释放没有用的对象。
关于栈和堆的更多内容
我们代码中有四种主要的类型需要存储在栈和堆当中:值类型,引用类型,指针和程序指令。
值类型:
在c#中主要的值类型有:
bool ,byte ,char ,decimal ,double ,enum ,float ,int ,long ,sbyte ,short ,struct ,uint ,ulong ,ushort都来自于System.TypeValue。
引用类型:
在C#中主要的引用类型有:class, interface, delegate,object,string所有的引用类型都继承自System.Object。
指针:
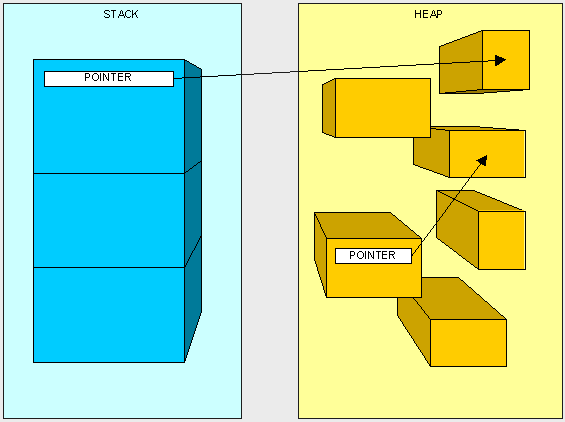
在我们的内存管理中一个指针的意义就是一个引用对应到一个类型上。在.net framework中我们不能显式的使用指针,所有的指针都被通用语言运行时(CLR)管理。指针是一块指向其他内存区域的内存区域。指针需要占据一定的内存空间就像其他任何数据一样。
指令就是计算机执行代码,如函数调用或是数据运算等。
内容和地址的问题
首先有两点需要说明:
- 1. 引用类型总是存在于堆里 – 很简单,但是完全正确吗?
- 2. 值类型和指针总是出现在他们声明的地方。这个有点复杂需要相关的栈工作原理的知识。
栈就像我们之前提到的那样,记录我们程序执行时的一些信息。当我们在调用一个类的方法时,操作系统将调用指令压栈并附带方法参数。然后进入函数体处理变量操作。这个可以用下面的代码来解释:
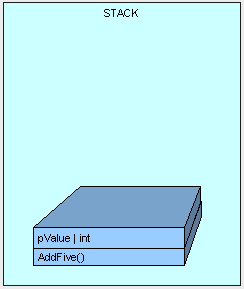
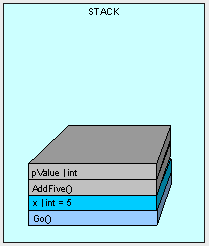
public int AddFive(int pValue) { int result; result = pValue + 5; return result; }
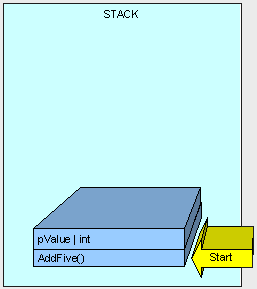
这个操作发生在栈的顶部,请注意我们看到已经有很多成员之前被压入到栈中了。首先是方法的本身先被压入栈中,紧接着是参数入栈。
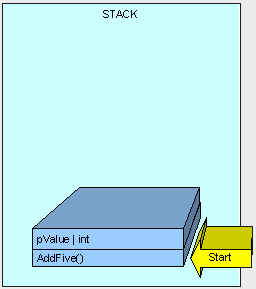
然后是通过AddFive()里面的指令来执行函数。
函数执行的结果同样也需要分配一些内存来存放,而这些内存也分配在栈中。
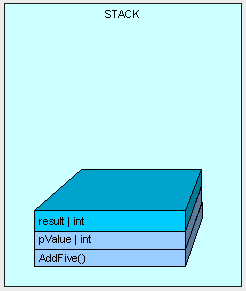
函数执行结束后,就要将结果返回。
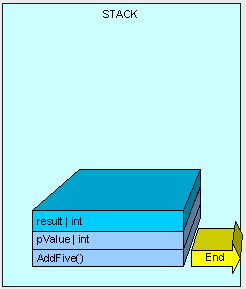
最后,通过删除AddFive()的指针来清除所有之前栈中有关于函数运行时分配的内存。并继续下一个函数(可能之前就存在在栈中)。
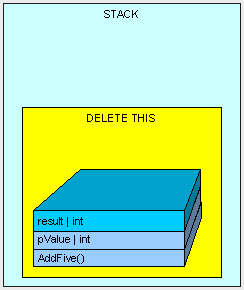
在这个例子中,我们的结果存储在栈中。事实上,所有函数体内的值类型声明都会分配到栈中。但是现在有些值类型也被分配在堆中。记住一个规则,值类型总是出现在声明它们的地方。如果一个值类型声明在函数体外,但是存于一个引用类型内,那么它将跟这个引用类型一样位于堆中。这里用另外的一个例子来说明这个问题:
public class MyInt{ public int MyValue;}
public MyInt AddFive(int pValue){ MyInt result = new MyInt(); result.MyValue = pValue + 5; return result;}
现在这个函数的执行跟先前的有了点不同。这里的函数返回是一个MyInt类对象,也就是说是一个引用类型。
引用类型是被分配在堆中的,而引用的指针是分配在栈中。
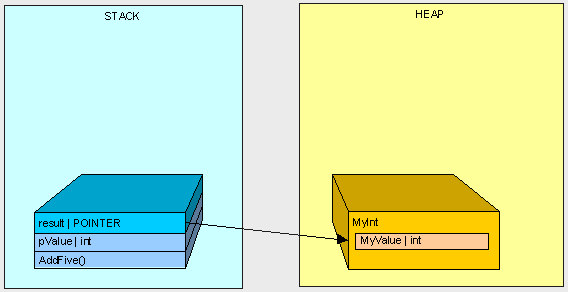
在AddFive()函数执行结束后,我们将清理栈中的内存。
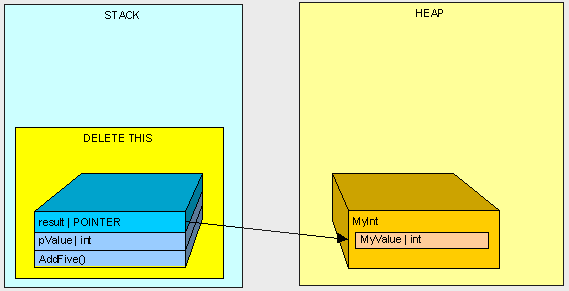
在这里我们看到除了栈中有数据,在堆中也有一些数据。而堆中的数据将被垃圾回收器回收。
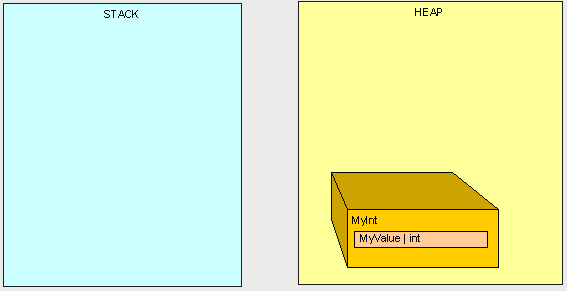
当我们的程序需要一块内存并且已经没有空闲的内存可以分配时,垃圾回收器开始运行。垃圾回收器会先停止所有运行中的线程,扫描堆中的所有对象并删除那些没有被主程序访问的对象。垃圾回收器将重新组织堆中的所有空闲的空间,并调整所有栈中和堆中的相关指针。就像你能想到的那样,这样的操作会非常的影响效率。因此这也是为什么我们要强调编写高性能的代码。好,那我要怎么样去做呢?
当我们在操作一个引用类型的时候,我们操作的是它的指针而不是它本身。当我们使用值类型的时候我们使用的是它本身,这个很明显。我们看一下代码:
public int ReturnValue() { int x = new int(); x = 3; int y = new int(); y = x; y = 4; return x; }
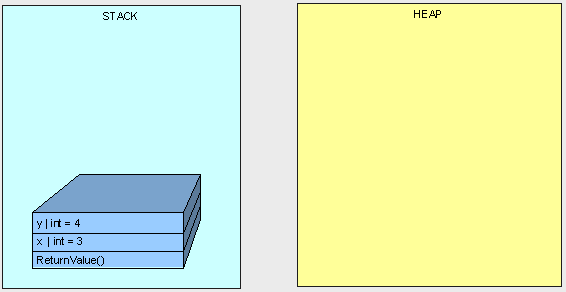
这段代码很简单,返回3。但是如果我们改用引用类型MyInt类,结果可能不同:
public class MyInt { public int MyValue; }
public int ReturnValue2() { MyInt x = new MyInt(); x.MyValue = 3; MyInt y = new MyInt(); y = x; y.MyValue = 4; return x.MyValue; }
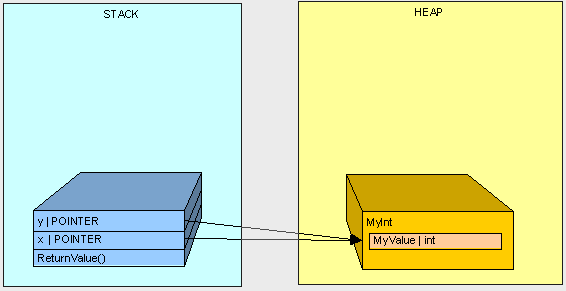
这里的返回值却是4。为什么呢? 想象一下,我们之前讲的内容,我们在操作值类型数据的时候只是操作该值的一个副本。而在操作引用类型数据的时候,我们操作的是该类型的指针,所以y = x就修改了y的指针内容,从而使得y也指向了x那一部分栈空间。所以y.MyValue = 4 => x.MyValue = 4。所以返回值会是4 。
参数
当我们开始调用一个方法的时候,发生了什么呢?
- 1. 在栈中分配我们方法所需的空间,包括回调的指针空间,该指针通过一条goto指令来回到函数调用开始的那个栈位置的下一个位置,以便继续执行。
- 2. 我们方法的参数将被拷贝过来。
- 3. 控制器通过JIT方法和线程开始执行代码,因此我们有了另外一个称呼叫调栈。
代码如下:
public int AddFive(int pValue){ int result; result = pValue + 5; return result;}
栈的结构模式:
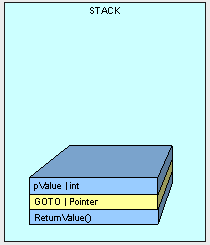
参数在栈中的位置取决于它的类型,值类型本身被拷贝而引用类型的引用被拷贝。
传递值类型参数
当我们传递一个值类型参数时,内存先被分配然后是值被拷贝到栈中。代码如下:
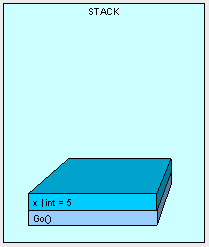
class Class1 {
public void Go () {
int x = 5;
AddFive(x);
Console.WriteLine(x.ToString());
}
public int AddFive (int pValue) {
pValue += 5;
return pValue;
}
}
AddFive方法被执行,x位置变成5
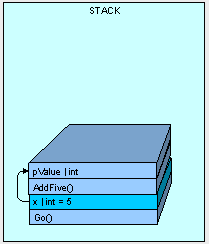
当AddFive()方法执行结束后,线程回到执行go方法,pValue将被删除。
所以当我们在传递一个很大的值类型的时候,程序会逐位的拷贝到栈中,这很明显就是效率很低。更何况我们的程序如果要传递这个值数千次的进行,那么效率就更低。
这时我们就要用到引用类型来解决这样的问题。
public void Go() {
MyStruct x = new MyStruct();
DoSomething(ref x);
}
public struct MyStruct {
long a, b, c, d, e, f, g, h, i, j, k, l, m;
}
public void DoSomething(ref MyStruct pValue) {
// DO SOMETHING HERE....
}
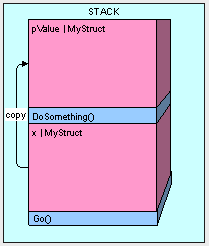
这种方法就更有效的进行操作内存,其实我们并不需要拷贝这块内存。
当我们传递的是值类型的引用,那么程序修改这个引用的内容都会直接反映到这个值上。
传递引用类型
传递引用类型参数有点类似于前面的传递值类型的引用。
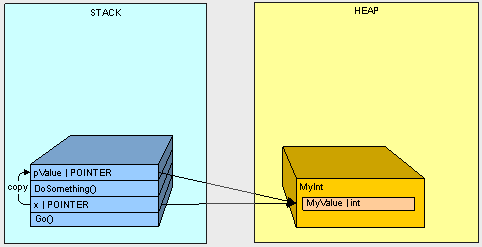
public class MyInt {
public int MyValue;
}
public void Go() {
MyInt x = new MyInt();
x.MyValue = 2;
DoSomething(x);
Console.WriteLine(x.MyValue.ToString());
}
public void DoSomething(MyInt pValue) {
pValue.MyValue = 12345;
}
这段代码做了如下工作:
- 1. 开始调用go()方法让x变量进栈。
- 2. 调用DoSomething()方法让参数pValue进栈
- 3. 然后x值拷贝到pValue
这里有一个有趣的问题是,如果传递一个引用类型的引用又会发生什么呢?
如果我们有两类:
public class Thing {
}
public class Animal : Thing {
public int Weight;
}
public class Vegetable : Thing {
public int Length;
}
我们要执行go()的方法,如下:
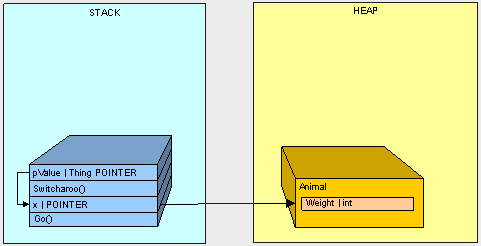
public void Go () {
Thing x = new Animal();
Switcharoo(ref x);
Console.WriteLine(
"x is Animal : "
+ (x is Animal).ToString());
Console.WriteLine(
"x is Vegetable : "
+ (x is Vegetable).ToString());
}
public void Switcharoo (ref Thing pValue) {
pValue = new Vegetable();
}
X的输出结果:
x is Animal : False
x is Vegetable : True
为什么是这样的结果呢?我们来看一下程序过程:
-
- Starting with the Go() method call, the x pointer goes on the stack
- The Animal goes on the hea
- Starting with the call to Switcharoo() method, the pValue goes on the stack and points to x
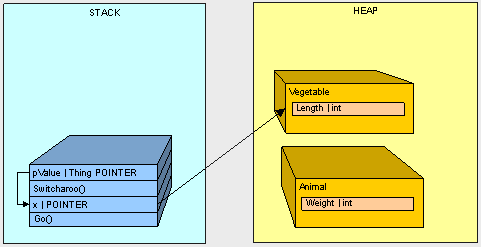
- The Vegetable goes on the heapthe heap
- The value of x is changed through pValue to the address of the Vegetable
如果我们没传递Thing对象的引用,那么我们将得到相反的结果。
拷贝和不拷贝
首先我们查看值类型,请使用下面的类和结构体。我们拥有一个Dude类包含个Name元素和2个Shoe。我们还有一个CopyDude()方法去产生一个新的Dude对象。
public struct Shoe {
public string Color;
}
public class Dude {
public string Name;
public Shoe RightShoe;
public Shoe LeftShoe;
public Dude CopyDude () {
Dude newPerson = new Dude();
newPerson.Name = Name;
newPerson.LeftShoe = LeftShoe;
newPerson.RightShoe = RightShoe;
return newPerson;
}
public override string ToString () {
return (Name + " : Dude!, I have a " + RightShoe.Color +
" shoe on my right foot, and a " +
LeftShoe.Color + " on my left foot.");
}
}
Dude类是一个引用类型并且因为Shoe结构是类的一个成员,所以它们都被分配到堆中。
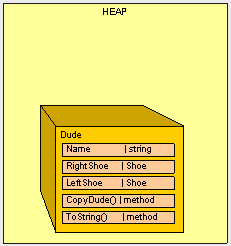
运行下面的程序:
public static void Main () {
Class1 pgm = new Class1();
Dude Bill = new Dude();
Bill.Name = "Bill";
Bill.LeftShoe = new Shoe();
Bill.RightShoe = new Shoe();
Bill.LeftShoe.Color = Bill.RightShoe.Color = "Blue";
Dude Ted = Bill.CopyDude();
Ted.Name = "Ted";
Ted.LeftShoe.Color = Ted.RightShoe.Color = "Red";
Console.WriteLine(Bill.ToString());
Console.WriteLine(Ted.ToString());
}
我们将得到如下的输出:
Bill : Dude!, I have a Blue shoe on my right foot, and a Blue on my left foot.
Ted : Dude!, I have a Red shoe on my right foot, and a Red on my left foot.
那么我们将Shoe声明为一个引用类型又会产生什么结果呢?
public class Shoe {
public string Color;
}
再次运行main()函数, 我们得到的结果是:
Bill : Dude!, I have a Red shoe on my right foot, and a Red on my left foot
Ted : Dude!, I have a Red shoe on my right foot, and a Red on my left foot明显Red shoe在Bill的脚上是错误的。为什么会这样呢?看一下图
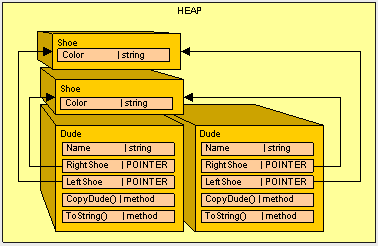
因为 我们使用Shoe作为一个引用类型来取代值类型。当一个引用被拷贝的时候,只拷贝了其指针,所以我们不得不做一些额外的工作来确保我们的引用类型看起来更像是值类型。
幸运的是我们拥有一个名为ICloneable接口可以帮助我们。这个接口基于一个契约,所有的Dude对象都将定义一个引用类型如何被复制以确保我们的Shoe不会发生共享错误。我们所有的类都可以使用ICloneable接口的clone方法来复制类对象。
public class Shoe : ICloneable {
public string Color;
#region ICloneable Members
public object Clone () {
Shoe newShoe = new Shoe();
newShoe.Color = Color.Clone() as string;
return newShoe;
}
#endregion
}
在Clone()方法内我们创建了一个Shoe,拷贝所有引用类型并拷贝所有值类型并返回一个新的对象实例。你可能注意到string类已经实现了ICloneable接口,因此我们可以调用Color.Clone()。因为Clone()返回的是一个对象的引用,我们不得不进行类型转换在我们设置Shoe的Color前。
接下来,我们用CopyDude()方法去克隆shoe。
public Dude CopyDude () {
Dude newPerson = new Dude();
newPerson.Name = Name;
newPerson.LeftShoe = LeftShoe.Clone() as Shoe;
newPerson.RightShoe = RightShoe.Clone() as Shoe;
return newPerson;
}
public static void Main () {
Class1 pgm = new Class1();
Dude Bill = new Dude();
Bill.Name = "Bill";
Bill.LeftShoe = new Shoe();
Bill.RightShoe = new Shoe();
Bill.LeftShoe.Color = Bill.RightShoe.Color = "Blue";
Dude Ted = Bill.CopyDude();
Ted.Name = "Ted";
Ted.LeftShoe.Color = Ted.RightShoe.Color = "Red";
Console.WriteLine(Bill.ToString());
Console.WriteLine(Ted.ToString());
}
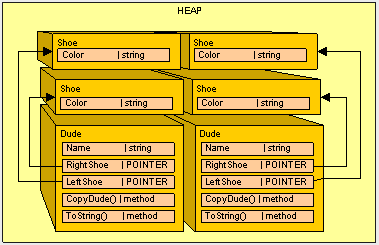
重新运行程序,我们将得到如下输出:
Bill : Dude!, I have a Blue shoe on my right foot, and a Blue on my left foot
Ted : Dude!, I have a Red shoe on my right foot, and a Red on my left foot图示如下:
包装实体
一般来说,我们总是想克隆一个引用类型和拷贝一个值类型。记住这点将有助于你解决调试时发生的错误。让我们更进一步分析并清理一下Dude类实现,使用ICloneable接口来代替CopyDude()方法。
public class Dude : ICloneable {
public string Name;
public Shoe RightShoe;
public Shoe LeftShoe;
public override string ToString () {
return (Name + " : Dude!, I have a " + RightShoe.Color +
" shoe on my right foot, and a " +
LeftShoe.Color + " on my left foot.");
}
#region ICloneable Members
public object Clone () {
Dude newPerson = new Dude();
newPerson.Name = Name.Clone() as string;
newPerson.LeftShoe = LeftShoe.Clone() as Shoe;
newPerson.RightShoe = RightShoe.Clone() as Shoe;
return newPerson;
}
#endregion
}
我们再来修改Main()中的方法:
public static void Main () {
Class1 pgm = new Class1();
Dude Bill = new Dude();
Bill.Name = "Bill";
Bill.LeftShoe = new Shoe();
Bill.RightShoe = new Shoe();
Bill.LeftShoe.Color = Bill.RightShoe.Color = "Blue";
Dude Ted = Bill.Clone() as Dude;
Ted.Name = "Ted";
Ted.LeftShoe.Color = Ted.RightShoe.Color = "Red";
Console.WriteLine(Bill.ToString());
Console.WriteLine(Ted.ToString());
}
最后,运行我们的程序,会得到如下的输出:
Bill : Dude!, I have a Blue shoe on my right foot, and a Blue on my left foot.
Ted : Dude!, I have a Red shoe on my right foot, and a Red on my left foot.还有些比较有意思的东西,比如System.String重载的操作符=号就实现了clones方法,因此你不用过于担心string类的引用复制问题。但是你要注意内存的消耗问题。如果你仔细查看上图,由于string是引用类型所以需要一个指针指向堆中的另一个对象,但是看起来它像是一个值类型。
图
接下来让我们从垃圾回收器的角度来看一下内存管理。如果我们想清理一下没用的东西我们可能需要计划一下怎么做才更有效率。很明显,我们需要先区分什么是垃圾,什么不是垃圾。那么我们要先做一个假设:任何东西如果没有用了那么就认为是垃圾。幸好我们身边有两位好朋友:即时编译器(JIT)和统一语言运行时(CLR)。JIT和CLR保持着一个列表关于它们正在使用的对象。我们将使用这个列表作为起始列表。我们将保持关于所有正在使用的对象到一个图表中。所有的活动的对象都将被添加到这个图表里。
这也是垃圾回收器所作的事情,从即时编译器和统一语言运行时那里得到一份关于所有根对象的引用列表。然后递归的查找活动对象的引用去建立一个图表。
根的组成如下:
l 全局/静态指针。一种方法确定我们的对象不会被垃圾回收通过保持他们的引用在一个静态变量里。
l 栈内指针。我们不想抛弃那些我们应用程序需要使用的东西。
l CPU寄存器指针。在托管堆里的任何被CPU寄存器的内存地址指向的对象都应该保留。
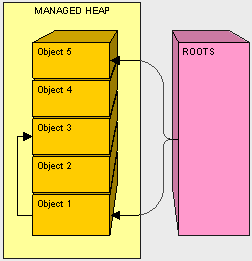
在上图当中,对象1和5都被roots直接引用,而对象3则在递归搜索中被发现被1引用。如果我们进行类比,那么对象1是可以看成遥控器,而对象3被看成远端的设备。当所有对象都进入图表中后,我们就进行下一步分析。
调整堆
现在我们已经将我们的要保留的对象加到图表中,现在我们可以分析一下这些东西。
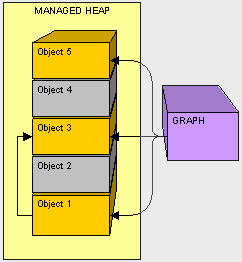
由于对象2是不需要的,所以就像垃圾回收器那样,我们下移对象3并修改对象1的指针。
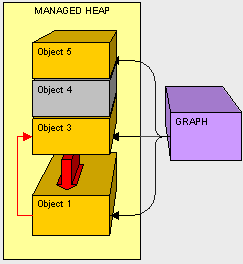
然后我们在将对象5下移。
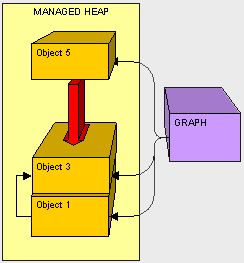
现在我们已经将托管堆进行了紧缩调整,为新来的对象腾出空间。
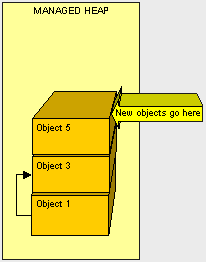
知道垃圾回收器的工作原理就知道移动对象的工作是很繁重的。从这里看出如果我们减少移动对象的大小就能提高垃圾回收器的工作效率,因为减少了拷贝内容。
托管堆之外
有时候垃圾回收器需要执行代码去清理非托管的资源诸如文件,数据库连接,网络连接等等。一种有效的控制这些内容的方式是终结器(finalizer)。
class Sample {
~Sample () {
// FINALIZER: CLEAN UP HERE
}
}
当对象在创建的时候,所有对象附带的终结器(finalizer)都会添加到终结队列里。我们可以说图中的对象1,4,5拥有终结器(finalizer)并都处于终结队列中。让我们看一下当对象2和4在没有被应用程序引用并且垃圾回收器准备好的情况下会发生什么。
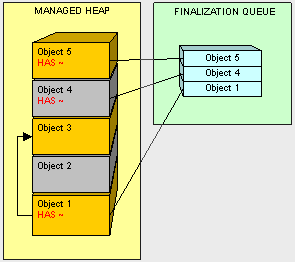
图里对象2被作为无用对象处理。但是,当我们处理对象4的时候,垃圾回收器会先查看它的终结队列并重新声明对象4所拥有的内存,对象4被移动并且它的终结器(finalizer)被添加到一个特殊的队列- freachable。
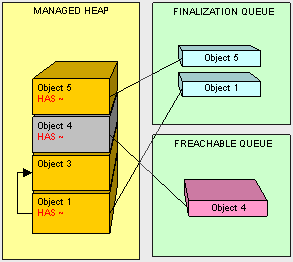
这里有专门的线程去处理freachable队列的成员。一旦对象4的终结器被线程执行,那么它就会从freachable队列中移除。然后对象4就可以被回收了。
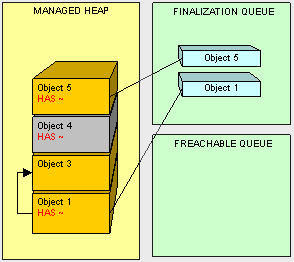
而对象4在下一次回收开始前仍然存在。
在创建对象时添加终结器(finalizer)是垃圾回收器的一个额外工作。它要花费很高的代价并且严重影响垃圾回收器和我们的应用程序的性能。所以请确定在绝对必要的情况下再使用终结器(finalizer)。
有更好的方案用作清理非托管资源。就像你想的那样,我们可以使用IDisposable接口取代终结器(finalizer)去关闭数据库链接并清理资源。
IDisposible
使用IDisposable接口的Dispose()方法做清理工作。因此如果我们有一个ResouceUser的类使用到了终结器(finalizer),如下:
public class ResourceUser {
~ResourceUser () // THIS IS A FINALIZER
{
// DO CLEANUP HERE
}
}
那么我们可以使用IDisposable来实验同样的功能:
public class ResourceUser : IDisposable {
#region IDisposable Members
public void Dispose () {
// CLEAN UP HERE!!!
}
#endregion
}
IDisposable已经被集成到了关键字中。在using()的最后Dispose()的代码块会被调用。对象不应该在Dispose()的代码块后被引用,因为它被标上了”gone”并且准备被垃圾回收器回收。
public static void DoSomething () {
ResourceUser rec = new ResourceUser();
using (rec) {
// DO SOMETHING
} // DISPOSE CALLED HERE
// DON'T ACCESS rec HERE
}
我喜欢把代码放在using块内,这样所有的变量和资源在块结束后回被自动回收(主要是因为using关键字扩展了后是try … finally …, 而所有的具有IDisposable接口的对象的Dispose()方法会在finally的代码块中被自动调用)。
public static void DoSomething () {
using (ResourceUser rec = new ResourceUser()) {
// DO SOMETHING
} // DISPOSE CALLED HERE
}
通过实现类的IDisposible接口,这样我们可以在垃圾回收器前通过强制方式释放我们的对象。
谨防静态变量
class Counter {
private static int s_Number = 0;
public static int GetNextNumber () {
int newNumber = s_Number;
// DO SOME STUFF
s_Number = newNumber + 1;
return newNumber;
}
}
如果同时有两个线程同时调用GetNextNumber()方法并同时为newNumber分配同样的变量在s_Num前。
那么两个线程同时将得到同样的返回值。为了解决这个问题,你需要去锁定一部分的代码块,使得竞争线程进入一个等待队列但是这样会降低效率。
class Counter {
private static int s_Number = 0;
public static int GetNextNumber () {
lock (typeof(Counter)) {
int newNumber = s_Number;
// DO SOME STUFF
newNumber += 1;
s_Number = newNumber;
return newNumber;
}
}
}
谨防静态变量2
接下来我们要关注引用类型的静态变量。记住,任何被根引用的对象都不能被清除。下面是一段代码:
class Olympics {
public static Collection<Runner> TryoutRunners;
}
class Runner {
private string _fileName;
private FileStream _fStream;
public void GetStats () {
FileInfo fInfo = new FileInfo(_fileName);
_fStream = _fileName.OpenRead();
}
}
因为Collection是存储Olympics类的静态集合,所以集合内的对象不会被垃圾回收器释放(因为它们都被root间接引用)。但是你可能要注意,每一次我们都要运行GetStats()来获取被打开文件流的状态。因为它们不能被关闭也不能被垃圾回收器释放而一直等待在那。想象一下我们如果有100000这样的对象存在,那么程序的性能就变得有多差。
单件
通过某种方式我们可以永久的保持一个对象实例在内存中。我们通过使用单件模式来实现。
单件可以看成是一个全局变量并且它会带来很多头疼的问题和奇怪的行为在多线程应用程序中。如果我们使用单模式,那么我们要进行适当的调整。
public class Earth {
private static Earth _instance = new Earth();
private Earth() { }
public static Earth GetInstance() { return _instance; }
}
我们拥有一个私有的构造器因此用户只能通过静态的GetInstance()方法来获取一个Earth实例。这是一个比较经典的线程安全实现,因为CLR会去创建安全的静态变量。这也是c#中我发现的最优雅的单件实现模式。
总结
- 1. 不要留下打开的资源!明确关闭所有连接和清理所有非托管资源。一个通用的规则在using块内使用非托管资源。
- 2. 不要过度的使用引用。当我们的对象活着,那么所有相关的引用对象将不会被回收。当我们操作了引用类的一些属性后,我们需要明确的将引用变量设置为null。以便垃圾回收器回收这些对象。
- 3. 使用终结器(finalizer)使工作更容易,但是是在必须的情况下。终结器(finalizer)需要花费垃圾回收器的昂贵的代价,所以必须在必要的时候使用它。一个更好的方案是使用IDisposible 接口来取代终结器(finalizer)。这样做会使垃圾回收器工作的更有效率。
- 4. 将对象和它们的孩子保持在一起。这样使得垃圾回收器更容易去产生大块内存而不用去收集托管堆上的每一个零散的内存。因此当我们声明一个对象由多个其他对象组合成的时候,我们应该显示的将它们安排的紧密一些。